
10,000 Stars in 10 Days: Reverse Engineering Claude Mythos
A project recently exploded on GitHub. Created on April 18, it amassed over 10,000 stars in just 10 days. The surprising part? The author, Kye Gomez, is just 22 years old. The project, named OpenMythos, is a mere 68 KB in size and implements a Recurrent-Depth Transformer using only PyTorch. In a nutshell, it’s a theoretical architecture reconstruction of Anthropic’s Claude Mythos, based on publicly available papers and community hypotheses. Why did a theoretical reconstruction project become so popular? Looking back, it has a lot to do with how Claude Mythos itself was released.
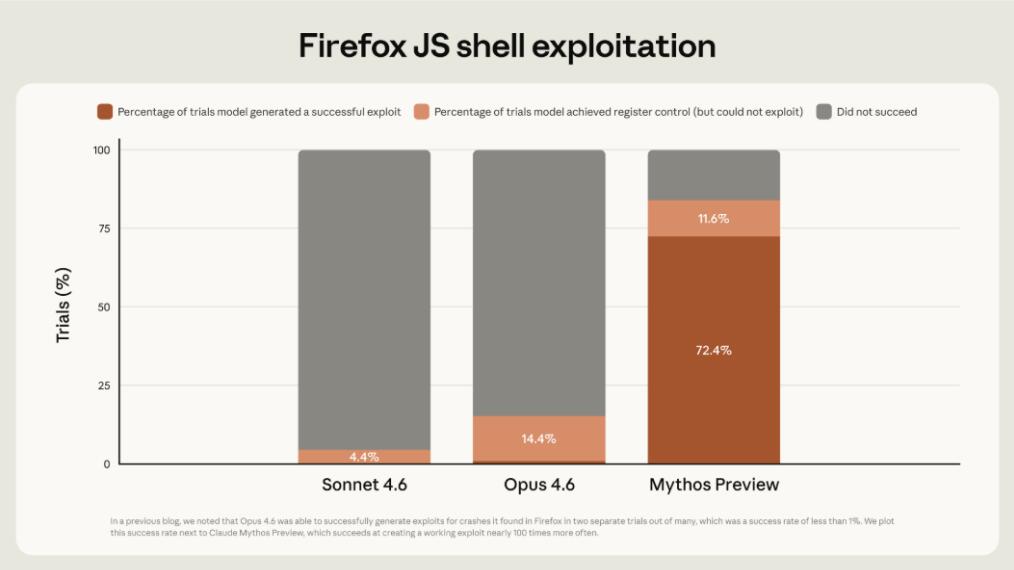
On April 7, Anthropic released Claude Mythos Preview. This wasn’t an ordinary model update but a new generation model more powerful than the current flagship, Opus. Official data shows it autonomously identified thousands of high-risk zero-day vulnerabilities, covering all mainstream operating systems and web browsers. It scored 83.1% on the CyberGym benchmark, surpassing nearly all top human experts in the field of cybersecurity. Mozilla reported that Mythos discovered 271 zero-day vulnerabilities in Firefox 148 source code, which were patched in Firefox version 150. However, Anthropic made a surprising decision: they refused to release it to the public, citing cybersecurity risks—the ability to find vulnerabilities could also be used for attacks.
I’ve compiled the vulnerability information disclosed by Anthropic. The model is only accessible to about 40–48 partners via the Project Glasswing program, including key infrastructure companies like Amazon, Apple, Microsoft, Google, CrowdStrike, Cisco, and JPMorgan Chase, specifically for defensive security research. This decision sparked debate in the community. Supporters viewed it as a responsible move, while skeptics argued the “danger narrative” might be exaggerated for marketing purposes. Independent security research institutions reproduced tests using smaller open-source models and found they could recover most of the analyses, questioning whether Mythos’s uniqueness was overstated. There were also reports that out of 7,000 vulnerabilities, only about 10 were critical. While these doubts may not negate Mythos’s value, they highlight a key issue: Anthropic has kept all technical details confidential, releasing only three documents—the System Card, Alignment Risk Update, and Responsible Scaling Policy—without disclosing the architecture design.
Online speculation has been rampant: what architecture does Mythos actually use? Models like OpenAI’s o1 and DeepSeek’s R1 work by generating “thinking tokens,” making their reasoning process explicit. But Mythos is different—it performs deep reasoning internally, without revealing intermediate steps. It is in this context that OpenMythos emerged and gained traction.
The author hypothesizes that Mythos likely uses a Recurrent-Depth Transformer, where the same set of weights is reused iteratively. Each loop performs a reasoning iteration in latent space, but no intermediate results are output externally. This resembles how humans think: first, we get a general idea, then we go deeper, fill in missing pieces, refine repeatedly, and finally consolidate and summarize the key points. The final answer appears concise, but internally, it has been polished and optimized multiple times. This hypothesis isn’t baseless—it references multiple recent papers, including “Loop, Think, & Generalize” (2026), “Parcae” (2026), and “Reasoning with Latent Thoughts” (2025). OpenMythos turns these theories into runnable code.
Traditional Transformers perform reasoning in a single pass: the model processes the input through a fixed number of layers and directly produces the output, without iterative refinement. OpenMythos divides the architecture into three segments: Prelude, Recurrent Block, and Coda. The recurrent block uses a single set of parameters that can be invoked repeatedly. With each additional loop, the internal state updates, allowing the model to think more deeply and comprehensively. The core formula for the loop looks like this: during each iteration, the original input e is reinjected. This prevents the hidden state from drifting in deep loops, much like how we periodically revisit the original problem while thinking to ensure we don’t stray off-topic.
While the project seems complex, installation requires just one command:
pip install open-mythos
You can then create a simple model in Python. For deeper reasoning, you can adjust the n_loopsparameter, though it requires more computation time. OpenMythos also supports two attention mechanisms: GQA and MLA. The FFN layer adopts a Mixture-of-Experts (MoE) design, splitting the original monolithic FFN into numerous smaller expert modules. During inference, a routing mechanism automatically selects the top k experts for each token, avoiding the need to run all experts. In addition to the routed experts, a small number of shared experts remain always active, capturing cross-domain general knowledge. The MoE routing mechanism works as follows: the shared experts prevent each routed expert from redundantly learning basics like grammar and elementary reasoning. The project provides seven preset configurations, ranging from 1B to 1T parameters, catering to various needs from experimentation to production. Training scripts are also provided, supporting both single-GPU and multi-GPU distributed training.

However, OpenMythos has also sparked controversy in the community. Supporters see it as groundbreaking work: the first complete implementation of a Recurrent-Depth Transformer, based on multiple top-tier papers, providing runnable PyTorch code and tools for the community to explore novel architectures. Critics point out that it’s just an architectural implementation without pre-trained weights, requiring massive resources for training from scratch; it’s uncertain whether it truly resembles Claude Mythos’s architecture; and the author, Kye Gomez, has a history with the Open-X series of projects, which some see as marketing open-source alternatives to closed-source models. It’s not exactly deceptive—the README clearly states it’s a theoretical reconstruction with no affiliation to Anthropic. But the way it spread… echoes the controversy surrounding Claude Mythos itself. Anthropic restricted Mythos’s public release for safety reasons, but critics argue this may widen the technological gap. Meanwhile, OpenMythos’s value needs validation through actual training results, not just theoretical claims.
Of course, OpenMythos has its own limitations. Without pre-trained weights, it requires training from scratch, which is a high barrier. Large-scale models (100B+ parameters) need distributed training, and long-context handling (1M tokens) demands substantial memory. While the LTI constraint theoretically stabilizes training and reduces fluctuations, its practical effectiveness must be confirmed through extensive testing. Additionally, more loops aren’t always better—excessive depth can lead to overthinking and over-reasoning, ultimately harming prediction accuracy.
Finally, a thought: previously, figuring out Claude Mythos’s architecture was pure speculation. With Anthropic withholding technical details, the community could only piece together clues from the System Card. OpenMythos represents someone turning theoretical papers into runnable code, making abstract hypotheses testable. When AI capabilities reach a certain threshold, the decision to release or withhold may be harder than the technical challenge itself. OpenMythos is still in its early stages, lacking pre-trained weights and requiring training from scratch. But the direction is right—giving the community a chance to explore novel architectures rather than waiting for official releases. If you’re interested in Recurrent-Depth Transformers, try running a minimal example to experience iterative reasoning. The project is open under the MIT license. Check out the GitHub repository for the source code and documentation.
Project address: https://github.com/kyegomez/OpenMythos

