
Another Offline Voice Cloning Tool Released as Open Source
Another powerful offline voice cloning tool has been released as open source. The popularity of ElevenLabs in 2023 highlighted the strong demand for AI speech synthesis. Everyone desires to create voiceovers with their own voice or clone a favorite timbre, leading many to subscribe to various online services. However, when most people eagerly try AI dubbing, reality looks like this: most online services typically follow a pattern where you must upload your data to the cloud and pay a subscription fee, often tens of dollars per month. Your voice samples and trained models are locked on someone else’s server. If the service raises prices or shuts down, you lose everything.
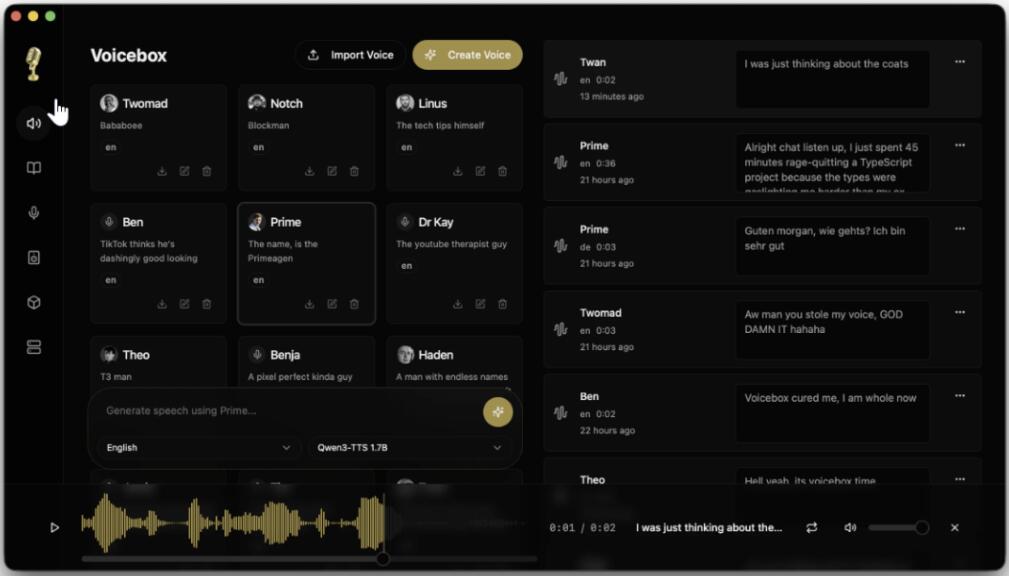
Some have experimented with open-source alternatives, but after much effort, they find that most tools remain at a “command-line” stage where getting any sound output is considered a success. Want to create multi-character dialogue? Add reverb to generated speech? Compare effects from different engines? Sorry, you have to piece it together yourself.
Recently, a project named Voicebox was open-sourced on GitHub. Its local voice cloning solution allows anyone to complete professional-grade voiceover production on their own computer. It has already garnered 21K stars on GitHub. It’s a fully local voice cloning workstation integrating 7 TTS engines, a multi-track editor, and a complete API. It can basically do everything ElevenLabs can, but it runs entirely on your own machine, for free.
Key Features:
- Local Operation: All inference, cloning, and generation happen on your device. Uses MLX/Metal on macOS (4-5x faster on Apple Silicon), CUDA on Windows, and supports AMD/Intel Arc.
- Multi-Track “Stories” Editor: A timeline editor for arranging dialogues, podcasts, or audiobooks with different voices on different tracks.
- 8 Built-in Audio Effects: Pitch shift, reverb, delay, compression, etc., using Spotify’s pedalboard library, with real-time preview.
- REST API: Full API for integration into other projects.
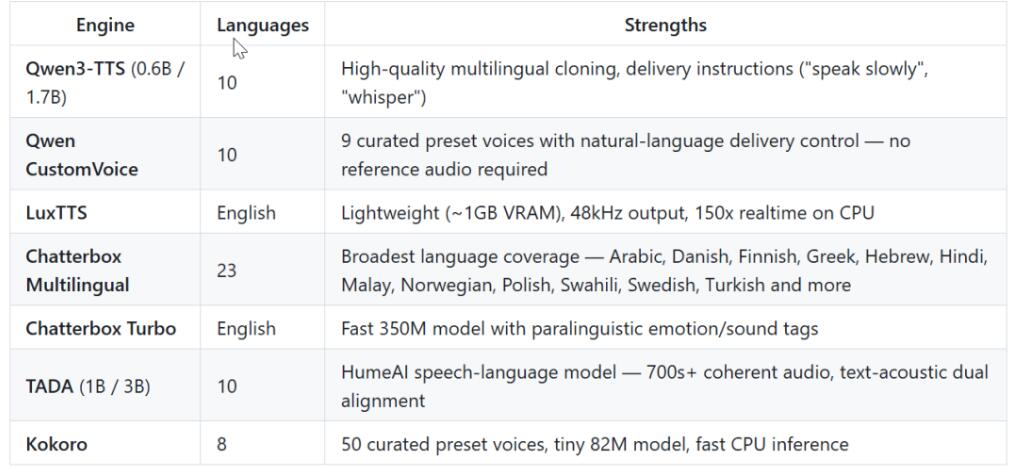
Core TTS Engines:
- Qwen3-TTS (by Alibaba): Main engine, 0.6B/1.7B models, supports 10 languages, high-quality cloning, accepts “performance instructions.”
- LuxTTS: Very fast, runs on 1GB VRAM, 150x real-time on CPU, 48kHz output. Ideal for quick drafts.
- Chatterbox Multilingual: Supports 23 languages, including Arabic, Finnish, Swahili.
- Chatterbox Turbo: 350M params, understands paralinguistic labels like
[laugh],[sigh]. - TADA: Long-form model, generates coherent audio over 700 seconds with phoneme-level timestamps.
- Kokoro: Smallest at 82M params, 50 curated preset voices, lowest hardware requirements.
Installation is straightforward. Download the installer from voicebox.sh(macOS/Windows) or use Docker. After launching, download models like Qwen3-TTS 1.7B, create a voice profile by recording or uploading audio, and start generating speech.
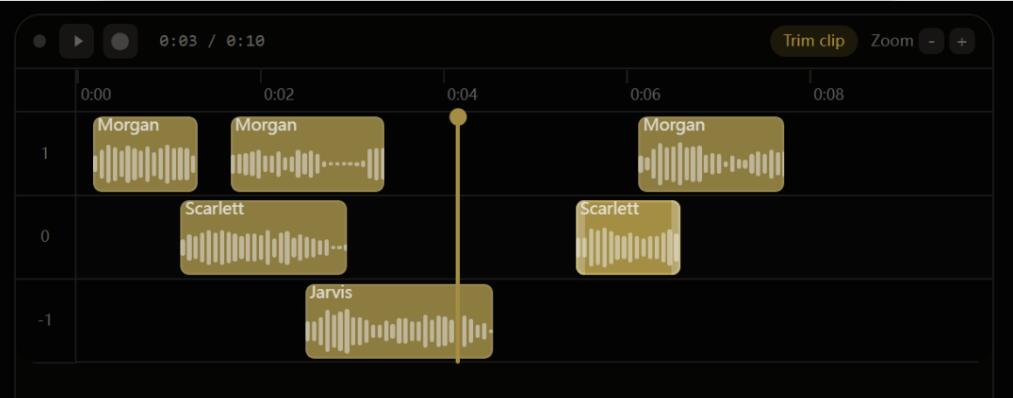
Use cases include multi-character audiobooks, podcast dialogue generation, and video dubbing with integrated post-processing.
The project, open-sourced under the MIT license, makes professional voice cloning accessible and secure, running on a standard computer without cloud dependency.
Project Address: https://github.com/jamiepine/voicebox

