
最近GitHubで話題になったプロジェクトがある。4月18日に作成され、わずか10日でスター数が1万を超えた。驚くべきは、作者のKye Gomezが今年たった22歳だということだ。このプロジェクトは「OpenMythos」と名付けられ、わずか68 KBのサイズで、PyTorchのみを用いてRecurrent-Depth Transformerを実装している。一言で言えば、公開論文とコミュニティの仮説に基づき、AnthropicのClaude Mythosの理論的アーキテクチャを再構築したものだ。なぜ理論的再構築プロジェクトがこれほど注目を集めたのか? 振り返ると、これはClaude Mythos自体の発表方法と大きく関係している。
4月7日、AnthropicはClaude Mythos Previewをリリースした。これは通常のモデルアップデートではなく、現行のフラッグシップOpusを上回る次世代モデルだった。公式データによると、主要なOSやWebブラウザの数千もの高危険度ゼロデイ脆弱性を自律的に識別。CyberGymベンチマークで83.1%のスコアを獲得し、サイバーセキュリティ分野ではほぼすべての人間のトップエキスパートを凌駕した。Mozillaの報告では、MythosはFirefox 148のソースコードで271個のゼロデイ脆弱性を発見し、Firefox 150で修正を完了した。しかし、Anthropicは驚くべき決定を下した。セキュリティリスクを理由に、一般公開を拒否したのだ。脆弱性を発見する能力が攻撃にも転用可能であるという理由からだ。
私がAnthropicが開示した脆弱性情報を整理してみた。モデルは「Project Glasswing」を通じて約40~48社のパートナーのみにアクセス権を提供。Amazon、Apple、Microsoft、Google、CrowdStrike、Cisco、JPMorgan Chaseといった重要インフラ企業が含まれ、防御的セキュリティ研究に専用されている。この決定はコミュニティで議論を呼んだ。支持者は「責任ある判断」と評価する一方、懐疑派は「危険性の物語がマーケティングに利用されている可能性」を指摘した。独立系セキュリティ研究機関が、より小さなオープンソースモデルで再現テストを行ったところ、分析の大部分を復元でき、Mythosの独自性が過大評価されているのではないかという疑問も呈された。また、7000個の脆弱性のうち、深刻なものは10個程度だったという報道もあった。これらの疑問がMythosの価値を否定するものではないにせよ、少なくとも一つの問題を浮き彫りにしている。Anthropicは技術的詳細を完全に秘匿し、System Card、Alignment Risk Update、Responsible Scaling Policyの3文書のみを公開し、アーキテクチャ設計は明かさなかったことだ。
ネット上ではずっと噂されていた。Mythosは結局どんなアーキテクチャを使っているのか? OpenAIのo1やDeepSeekのR1は、思考トークンを生成することで推論過程を明示的に示している。しかしMythosは異なる。モデル内部で深い思考を完結させ、中間の推論ステップを一切出力しない。そうした状況の中、OpenMythosは登場し、話題となった。
作者の仮説はこうだ。Mythosは「Recurrent-Depth Transformer(循環深層トランスフォーマー)」を使用している可能性が高い。同一の重みを繰り返し使用し、各ループで潜在空間内で推論イテレーションを行うが、外部には中間結果を一切出力しない。これは我々が普段考えるプロセスに似ている。まず大枠を整理し、次に深く考えて漏れた詳細を補い、何度も練り直した後、最後に要点を抽出して統合する。最終的に提示される答えは簡潔に見えるが、実は頭の中で何度も推敲・最適化されているのだ。作者のこの仮説は空想ではない。Loop, Think, & Generalize(2026)、Parcae(2026)、Reasoning with Latent Thoughts(2025)といった複数の最近の論文を参照している。OpenMythosはこれらの理論を、実行可能なコードに落とし込んだ。
従来のTransformerの推論は一発処理だ。モデルは入力を受け取り、固定層数を一度だけ処理して結果を出力する。反復的な推敲はない。OpenMythosはアーキテクチャを3段階、すなわちPrelude、Recurrent Block、Codaに分ける。ループ部は一組のパラメータを使い回し、繰り返し実行される。ループを重ねるごとに内部状態が更新され、モデルは徐々により深く、より包括的に思考できるようになる。ループの核となる式は次のようなものだ。各ループで、元の入力eが再注入される。これは隠れ状態が深いループで「ドリフト」(目標から外れること)するのを防ぐためだ。思考中に、時折問題自体を見返して脱線しないようにするのと似ている。

このプロジェクトは複雑に見えるが、インストールはたった1行だ。
pip install open-mythos
その後、Pythonで簡単なモデルを作成できる。より深い推論が必要な場合はn_loopsパラメータを調整可能だが、より多くの計算時間が必要となる。OpenMythosはGQAとMLAという2つの注意機構もサポートする。FFN層は混合専門家(MoE)設計に置き換えられ、元の一枚岩のFFNを多数の小型エキスパートモジュールに分割する。推論時、ルーティング機構が各トークンに最適な上位k個のエキスパートを自動的に選択し、全エキスパートを実行する必要がなくなる。ルーティングで選択されたエキスパートに加え、少数の共有エキスパートが常に活性化状態を保ち、分野横断的な汎用知識を吸収する。MoEのルーティング機構は次の通り。共有エキスパートは、各ルーティングエキスパートが文法や基礎推論などの基本的な内容を重複して学習するのを防ぐ。プロジェクトは1Bから1Tまでの7種類のプリセット構成を提供し、実験から本番運用まで様々なニーズに対応する。トレーニングスクリプトも用意されており、シングルGPUとマルチGPU分散トレーニングの両方をサポートする。
しかし、OpenMythosはコミュニティ内で論争も引き起こした。支持者は「画期的な仕事」と評価する。Recurrent-Depth Transformerの初の完全実装であり、複数のトップ論文に基づき、実行可能なPyTorchコードを提供。コミュニティが新アーキテクチャを探求するためのツールとなった。一方、懐疑派は指摘する。これはアーキテクチャ実装に過ぎず、事前学習済み重みはない。ゼロからトレーニングするには膨大なリソースが必要。Claude Mythosアーキテクチャに本当に近いかは不確か。作者Kye Gomezの「Open-X」シリーズプロジェクトには、クローズドソースモデルに対するオープンソース対抗馬というマーケティングの意図が疑われる、と。完全な詐欺とは言えない。README冒頭で「理論的再構築であり、Anthropicとは一切無関係」と明言しているからだ。しかし、その伝搬のされ方は… まさにClaude Mythos自体の論争と共振している。Anthropicは安全を理由にMythosの一般公開を制限したが、批判派はこれが技術格差を拡大すると主張する。同時に、OpenMythosの真の価値は、理論的側面だけではなく、実際のトレーニング結果による検証が必要だ。
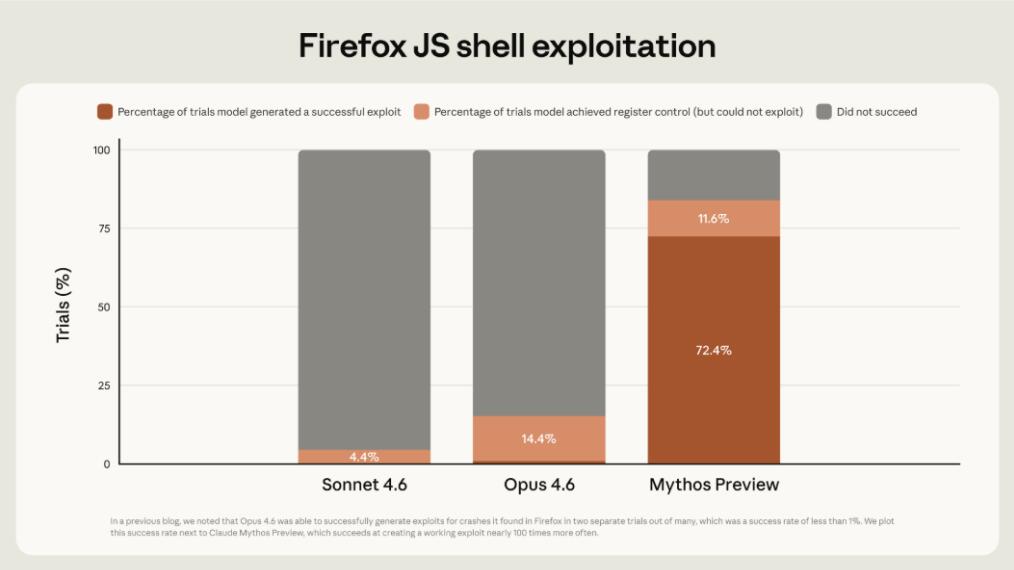
もちろんOpenMythos自体にも限界はある。事前学習済み重みがなく、ゼロからのトレーニングが必要で、ハードルが高い。大規模モデル(100B+)は分散トレーニングが必要で、長文脈(100万トークン)には大量のメモリが必要だ。LTI制約は理論的にはトレーニングを安定させ変動を減らすが、実際の有効性は大量の実測で確認する必要がある。また、ループは多ければ多いほど良いわけではなく、深すぎるとモデルが「考えすぎ」に陥り、過剰推論(over-reasoning)の末、予測精度に悪影響を及ぼす可能性もある。
最後に、以前はClaude Mythosのアーキテクチャを知るには、推測するしかなかった。Anthropicが技術詳細を公開しないため、コミュニティはSystem Cardの断片から手がかりを紡ぐしかなかった。OpenMythosの登場により、誰かが論文の理論を実行可能なコードに変え、抽象的な仮説を検証可能にしたと言える。AIの能力がある臨界点に達した後、「公開できるか」よりも「公開する勇気があるか」の方が難しい決断になることもある。OpenMythosはまだ初期段階にあり、事前学習済み重みがなく、ゼロからのトレーニングが必要だ。しかし方向性は正しい。コミュニティに新アーキテクチャを探求する機会を与え、公式オープンソースを待つだけではない選択肢を提供する。Recurrent-Depth Transformerに興味があるなら、最小限のサンプルを実行し、ループ推論のプロセスを体感してみるといいだろう。プロジェクトはMITライセンスで公開されている。ソースコードとドキュメントはGitHubリポジトリで確認できる。
プロジェクトアドレス: https://github.com/kyegomez/OpenMythos

