
Les « nouvelles pinces » de l’écrevisse en Open Source ! 3,1K étoiles sur GitHub
Faire en sorte qu’un Agent IA consulte les tendances ou effectue une recherche sur X peut sembler simple. Mais pour le faire fonctionner de manière stable, il y a de nombreux problèmes à prendre en compte. On peut chercher une clé API, mais 99 % des sites n’en ont pas. On peut écrire un scraper — le code casse lorsque le site est modifié, et il faut craindre d’être bloqué. On peut utiliser un navigateur sans tête comme Playwright — se reconnecter à chaque fois, gérer les cookies, et le site peut toujours détecter que vous êtes un robot. Le plus frustrant ? Votre navigateur Chrome est déjà connecté à tous les sites, mais l’Agent doit tout recommencer depuis le début.
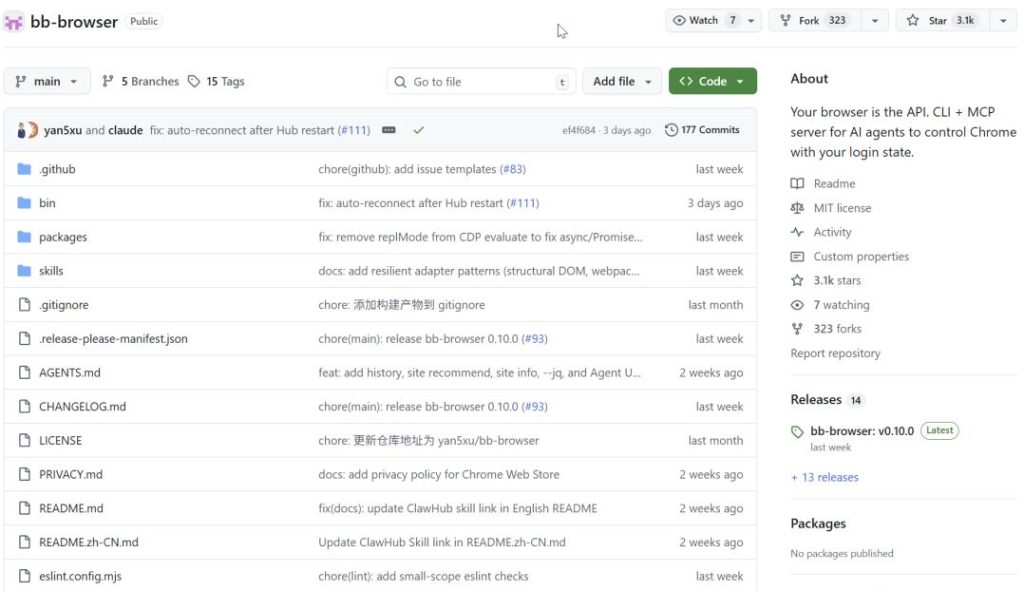
Il existe un projet sur GitHub appelé bb-browser. BadBoy Browser. Un navigateur « mauvais garçon ». Le projet est open-source et compte actuellement 3,1K étoiles. Le développeur a posté une longue histoire sur Reddit r/LocalLLaMA concernant l’origine du projet, déclenchant une propagation virale. Il a été discuté en première page de Hacker News, recommandé sur des colonnes Zhihu, et débattu avec passion dans la communauté Jike. Même l’auteur a admis que l’approche est « mauvaise ». Mais elle est élégante au point d’être irréfutable.
Un moment « Eurêka »
Le développeur a expliqué l’origine du projet sur Reddit. Au départ, il s’agissait simplement de permettre à un Agent IA d’accéder à Reddit. Les solutions traditionnelles étaient toutes gênantes — reconnexion, gestion des cookies, lutte contre les restrictions. Puis il a regardé son Chrome déjà connecté et a pensé : je suis déjà connecté, pourquoi devrais-je tout refaire ? Pourquoi ne pas exécuter le code directement dansle navigateur ?
Il a essayé. Il a appelé le module webpack sur la page X, a fait signer les requêtes par la page elle-même. Statut 200. Les résultats de recherche sont revenus parfaitement. Il a fixé l’écran un bon moment — cette chose s’exécutait dans son vrainavigateur, utilisant son vraiétat de connexion. Le site ne pouvait littéralement pas faire la différence avec lui utilisant le site normalement. Comme il l’a dit sur Reddit : « Le site ne peut littéralement pas faire la différence entre cela et moi l’utilisant normalement.«
Ce moment a décidé du nom du projet : bb-browser, BadBoy Browser, le navigateur mauvais garçon. « L’approche est mauvaise. Mais elle est tellement élégante.«
L’idée centrale tient en une phrase : utiliser directement votre vrai navigateur déjà connecté. L’Agent IA exécute du code dans votre Chrome, utilise votre état de connexion et récupère du JSON structuré. Le site le voit comme vous en train d’opérer.
36 plateformes, toutes écrites par la communauté
Dans le dépôt bb-sites, il y a un fichier JS par commande. X, Reddit, GitHub, StackOverflow, Bilibili, arXiv — pratiquement tous les sites auxquels vous pouvez penser ont un adaptateur déjà écrit par quelqu’un.
bashbashbb-browser site twitter/search "agent IA"
bb-browser site zhihu/hot
bb-browser site arxiv/search "transformer"
bb-browser site eastmoney/stock "Maotai"
Tout renvoie du JSON structuré. Titre, lien, popularité — tout ce qu’il faut. Toutes les commandes prennent en charge la sortie --jsonet même le filtrage en ligne --jq:
bashbashbb-browser site xueqiu/hot-stock 5 --jq '.items[] | {name, changePercent}'
Vous donne des données filtrées directement.
Transformer n’importe quel site en CLI en 10 minutes
Ce qui est encore plus fou, c’est ça. Vous dites à l’Agent IA : « Aide-moi à rendre le site XX accessible via CLI. » L’Agent lit automatiquement le tutoriel, utilise bb-browser network --with-bodypour faire de la rétro-ingénierie des requêtes réseau, écrit l’adaptateur, le teste et soumet une PR au dépôt communautaire. Tout le processus est automatique. L’auteur a testé avec 20 Agents IA fonctionnant en concurrence, chacun faisant de la rétro-ingénierie d’un site différent, et tous ont réussi. Il a dit : « Le coût marginal pour rendre un nouveau site accessible à un Agent tend vers zéro. » C’est une déclaration forte.
Un Agent peut faire une recherche multi-plateforme en une minute : chercher des articles académiques sur arXiv, voir les discussions sociales sur X, trouver des projets open source sur GitHub, chercher des questions-réponses techniques sur StackOverflow, vérifier les communautés chinoises sur Zhihu, lire les nouvelles de l’industrie sur 36Kr. Six plateformes, six dimensions, tout en JSON structuré. Plus rapide qu’aucun chercheur humain.
Trois commandes
bashbashnpm install -g bb-browser
bb-browser site update
bb-browser site zhihu/hot
Installer, récupérer les adaptateurs, et c’est parti.
Trois modes de fonctionnement : Mode OpenClaw (--openclaw, utilise le navigateur intégré d’OpenClaw, pas besoin d’extension), mode extension Chrome, mode MCP (intégration avec Claude Code / Cursor).
Problèmes connus :
- Sous Windows,
--openclawpeut donner une erreurspawnSync npx ENOENT; utilisez--portpour spécifier un port CDP. - macOS a des problèmes IPv6 ; le Daemon a besoin de
--host 127.0.0.1pour se lier à IPv4.
Note de sécurité : Quelqu’un a réalisé un audit de sécurité et a trouvé 4 vulnérabilités critiques — zéro authentification, CORS wildcard, injection eval. L’auteur les a depuis corrigées. Mais un mot de prudence : N’exécutez pas bb-browser lorsque vous êtes connecté à votre compte bancaire. Cette approche d' »usurpation d’utilisateur » pourrait violer les Conditions d’utilisation de certains sites. Soyez conscient en l’utilisant.
Adresse GitHub : https://github.com/epiral/bb-browser
« Internet a été conçu pour les navigateurs. Les Agents IA ont essayé d’y accéder via des API, mais 99% des sites n’ont pas d’API. bb-browser fait l’inverse : au lieu de forcer les sites à fournir des interfaces machine, laissons la machine utiliser l’interface humaine directement. »
BadBoy Browser. L’approche est mauvaise, mais elle est en effet élégante.
